 Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Abstract
Contrastive Language-Image Pre-training (CLIP) plays an essential role in extracting valuable content information from images across diverse tasks. It aligns textual and visual modalities to comprehend the entire image, including all the details, even those irrelevant to specific tasks. However, for a finer understanding and controlled editing of images, it becomes crucial to focus on specific regions of interest, which can be indicated as points, masks, or boxes by humans or perception models.
To fulfill the requirements, we introduce Alpha-CLIP, an enhanced version of CLIP with an auxiliary alpha channel to suggest attentive regions and fine-tuned with constructed millions of RGBA region-text pairs. Alpha-CLIP not only preserves the visual recognition ability of CLIP but also enables precise control over the emphasis of image contents. It demonstrates effectiveness in various tasks, including but not limited to open-world recognition, multimodal large language models, and conditional 2D / 3D generation. It has a strong potential to serve as a versatile tool for image-related tasks. All the code, models, and training data will be publicly available.
Video
🔥Highlight
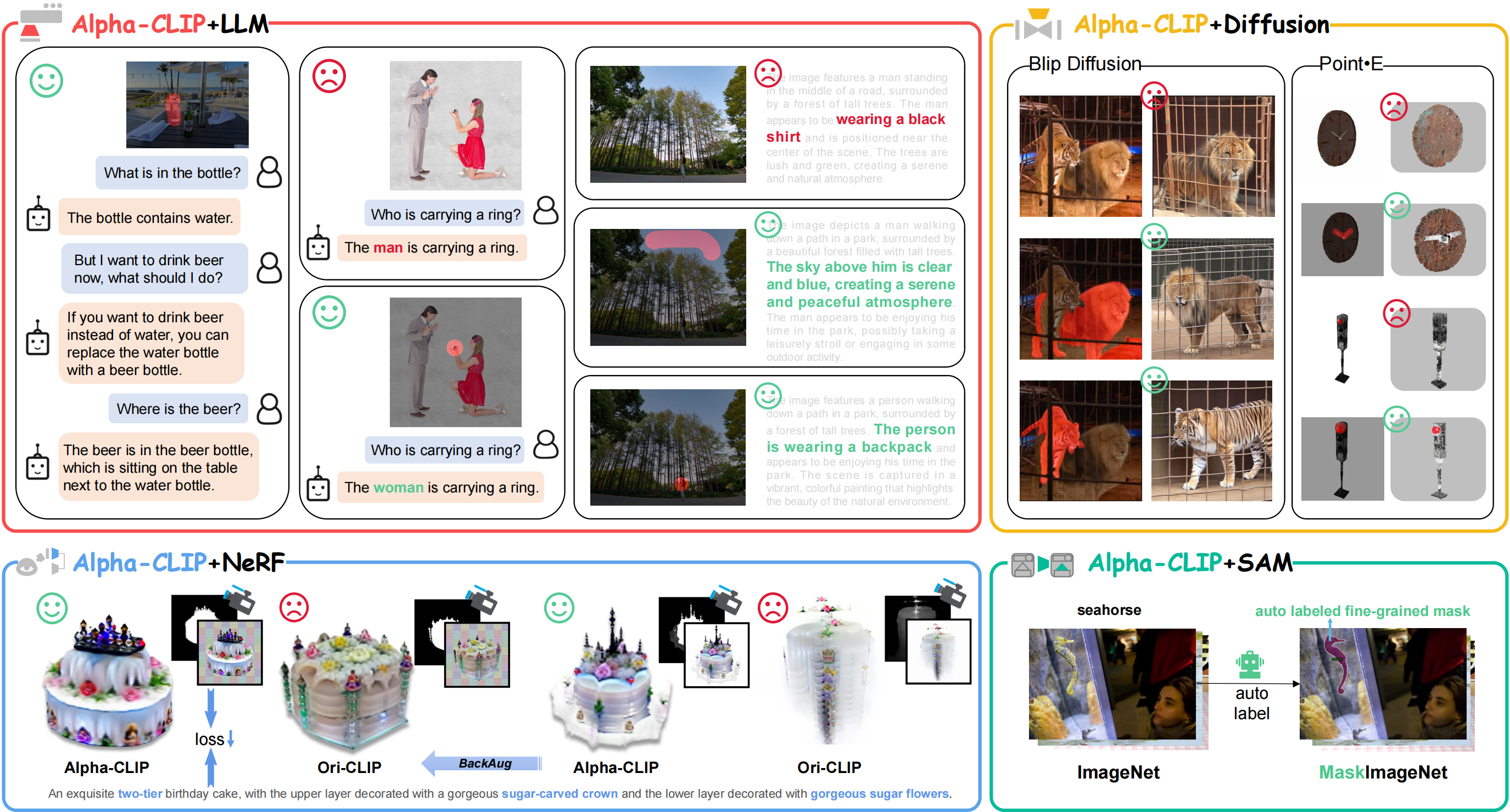
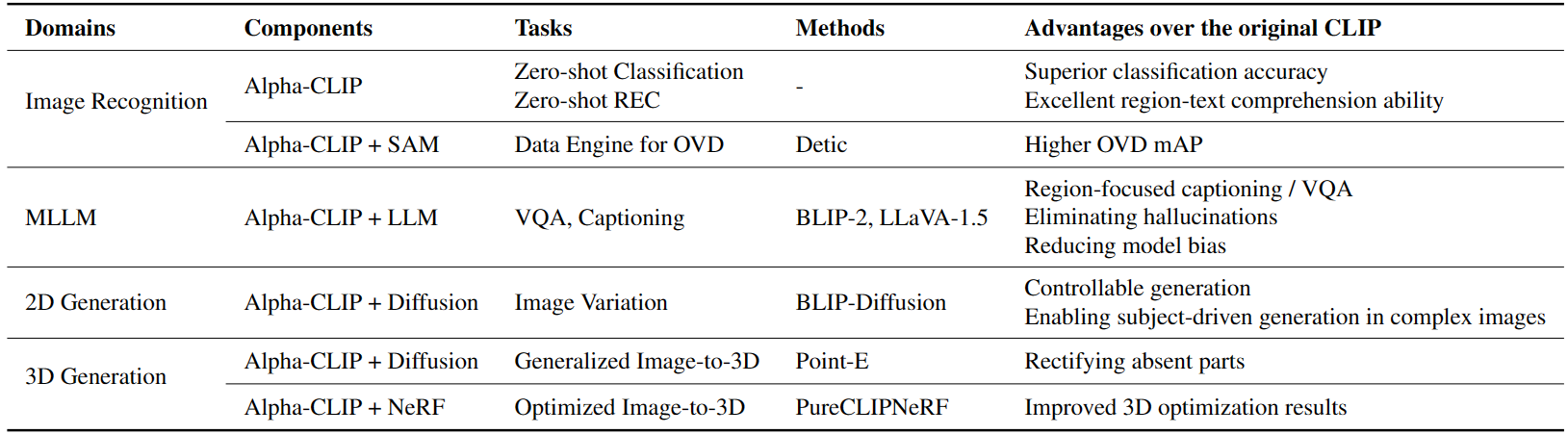
- Alpha-CLIP in Image Recognition. Focusing on a specified ground-truth region leads to a 4.1% increase in top-1 accuracy for the zero-shot ImageNet classification task. This enhanced region-based recognition is valuable for tasks like Referring Expression Comprehension(REC) and serves as data engine for Open Vocabulary Detection(OVD).
- Serving as vision backbone in MLLM. In conjunction with a large language model, Alpha-CLIP becomes capable of facilitating region level captioning and VQA within a MLLM framework(e.g. BLIP-2, LLaVA). This integration significantly mitigates the occurrences of hallucinations and diminishes model bias, while also empowers region-focused new tasks.
- Alpha-CLIP in 2D generation. When integrated with a diffusion model, Alpha-CLIP enhances the controllability of BLIP-Diffusion in image variation tasks. In addition, it enables the extraction of subjects from complex images for subject-driven generation, surmounting an obstacle encountered when deploying BLIP-Diffusion with the original CLIP, which only supports single subjects in simplistic images.
- Alpha-CLIP in 3D generation. In addition to the capabilities in 2D generation, Alpha-CLIP exhibits proficiency in 3D generation as well. It can be effectively deployed in conjunction with a diffusion model, such as Point-E, to enhance the quality of 3D object generation. Additionally, it can be utilized with NeRF, exemplified by PureCLIPNeRF, to optimize the creation of superior 3D objects.
Alpha-CLIP Usage
Alpha-CLIP can enhance CLIP across a wide array of downstream tasks, applying a plug-and-play methodology that permeates diverse domains, spanning from perception to generation in 2D and 3D applications. We show downstream tasks of Alpha-CLIP and their advantages over the original CLIP in the following figure and table.
Alpha-CLIP in Image Recognition
Alpha-CLIP boosts the capability of region-based recognition for original CLIP. We set alpha channel input to all one according to areas of interest to obtain precise object categories in complex images. The illustration are as follows.
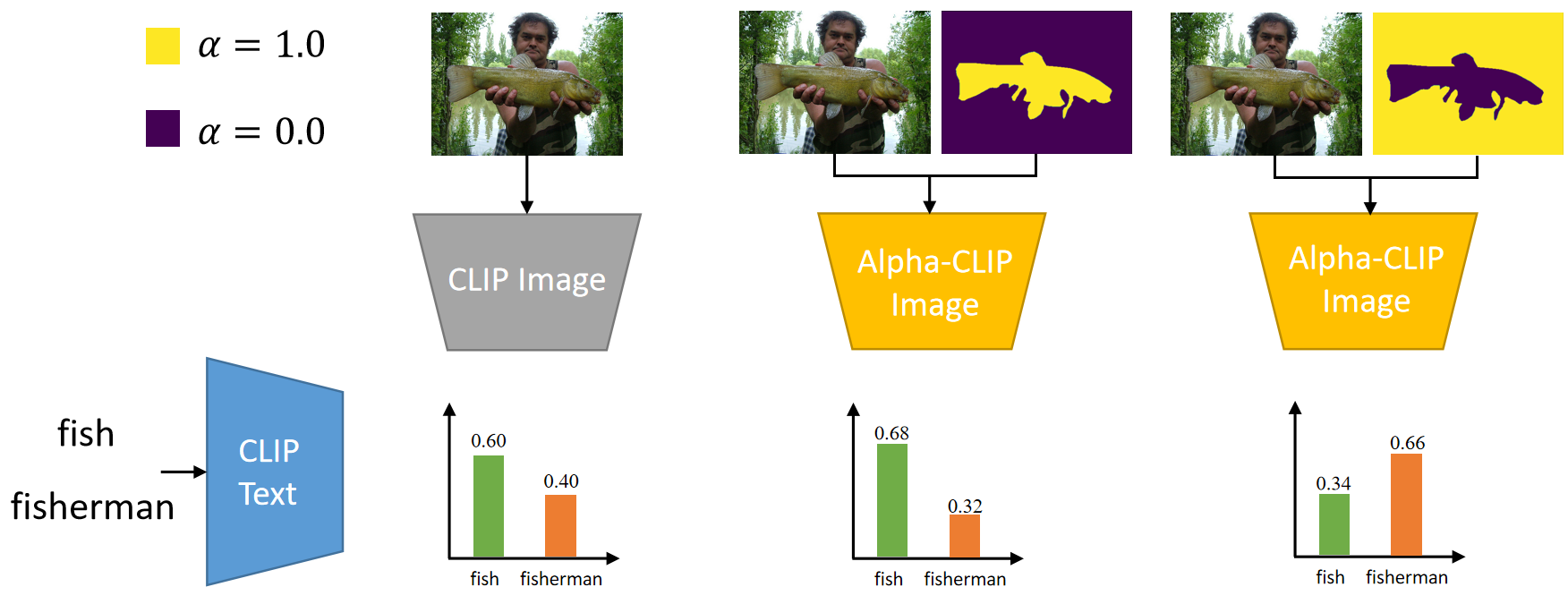
We test both original CLIP and Alpha-CLIP's recognition ability with different alpha-map levels on ImageNet. The results are as follows.
| Model | Alpha Map | Top-1 | Top-5 |
|---|---|---|---|
| CLIP | - | 73.48 | 91.60 |
Alpha-CLIP |
whole image | 73.37 | 91.75 |
| rectangular box | 75.62 | 93.34 | |
| mask | 77.41 | 94.45 |
Alpha-CLIP in MLLM
We replace CLIP used in BLIP-2 and LLaVA-1.5 with our Alpha-CLIP to make MLLM directly focus on user-defined region in vision-language tasks such as region level captioning and VQA. All cases shown here are made simply by replacing the original CLIP of BLIP2 or LLaVA-1.5 with a plug-in Alpha-CLIP without further tuning.
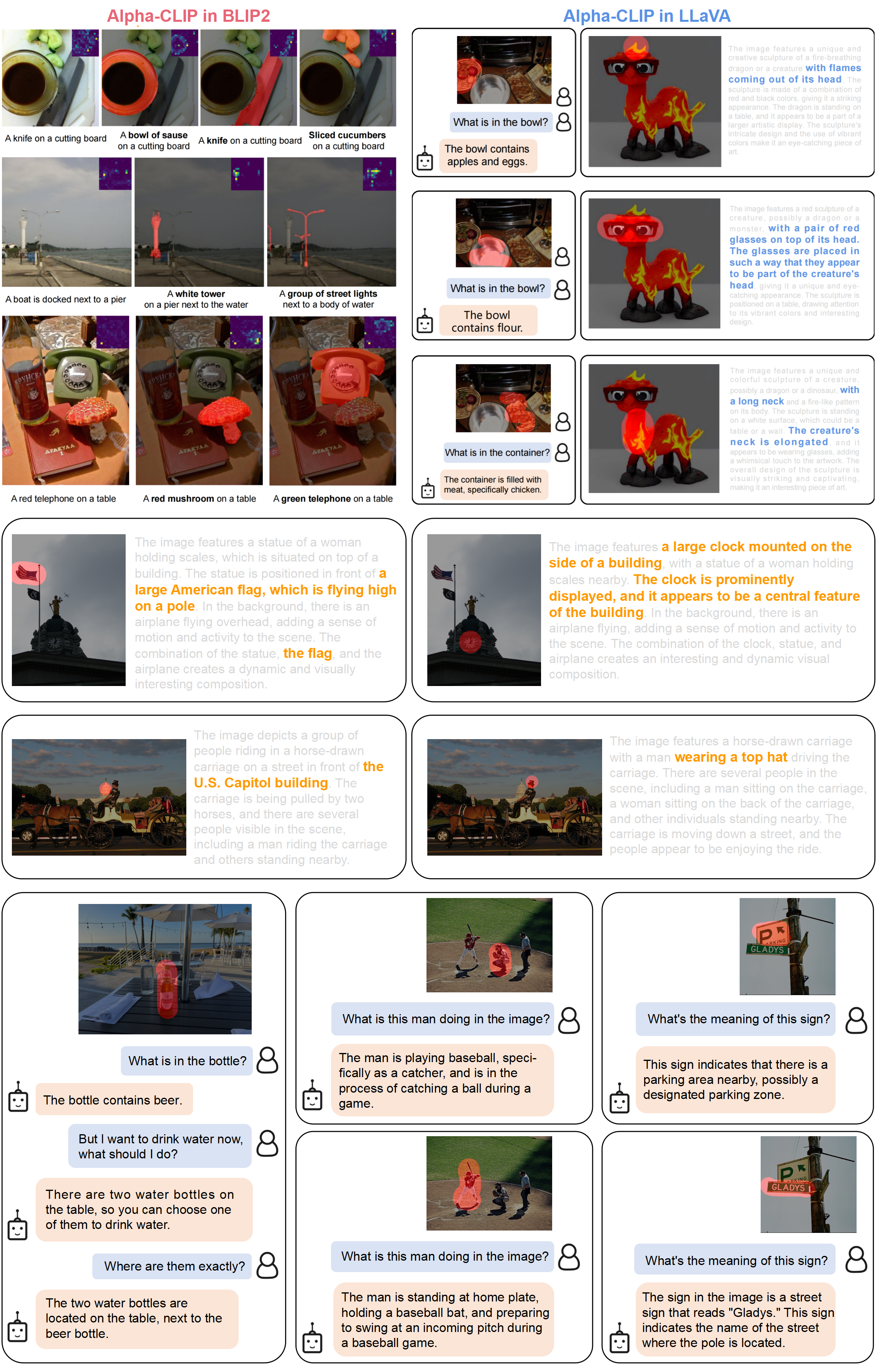
Besides qualitative results, we also provide quantitative region captioning results of Alpha-CLIP with LLaVA-1.5 on Visual Genome and RefCOCOg.
| Model | refCOCOg | Visual Genome | ||
|---|---|---|---|---|
| METEOR | CIDEr | METEOR | CIDEr | |
| GRIT | 15.2 | 71.6 | 17.1 | 142 |
| Kosmos-2 | 14.1 | 62.3 | - | - |
| GPT4RoI | - | - | 17.4 | 145.2 |
| GLaMM | 16.2 | 105.0 | 18.6 | 157.8 |
| Alpha-CLIP+LLaVA | 16.7 | 109.2 | 18.9 | 160.3 |
Alpha-CLIP in Image Variation
Alpha-CLIP can be used in most image variation models that use CLIP image encoder. For example, BLIP-Diffusion bridges CLIP and stable-diffusion with Q-former to generate and edit 2D images controlled by text. By introducing Alpha-CLIP, we can add an additional set of vision prompts to allow the model to focus on specified regions for 2D generation, enabling subject-driven generation in complex images. The first row per three is the original BLIP-Diffusion generated
images. Other rows represent the outcomes of Alpha-CLIP with highlighted regions marked in red.

Alpha-CLIP in 3D Object Generation
Alpha-CLIP in Point-E
We demonstrate that Alpha-CLIP is helpful in two cases:- When Point-E generates the point cloud with some parts missing, users can highlight the missing part in the condition image to remind the diffusion model to pay more attention to that part and fix this missing parts problem.
- Users can highlight the part that needs to be emphasized on the 2D image.

Alpha-CLIP in PureCLIPNeRF
We replace CLIP model with Alpha-CLIP in PureCLIPNeRF to generate 3D objects, and tests are conducted with and without background augmentation. As shown in the following figure, with Alpha-CLIP, PureCLIPNeRF generates objects that closely align with the provided textual prompts(especially bolded text) in terms of shape and color. Furthermore, there is an enhancement in the overall coherence of the generated objects, coupled with notable aesthetic qualities.



A beautifully carved square fountain with an ornate statue standing in the center.
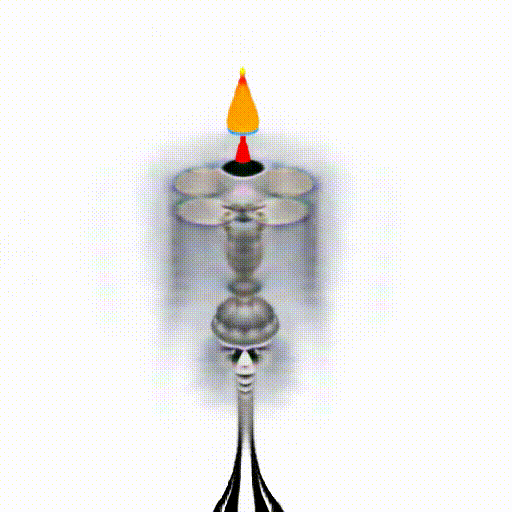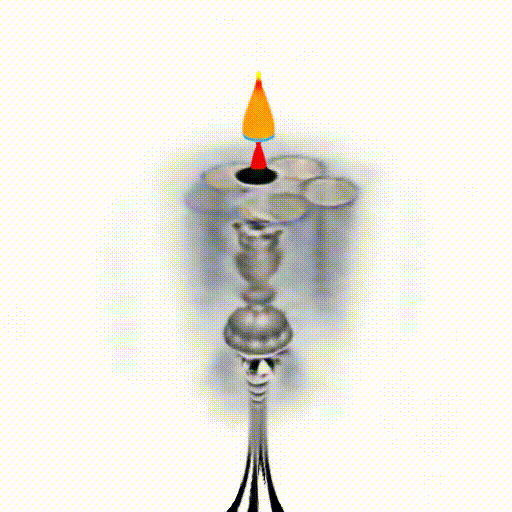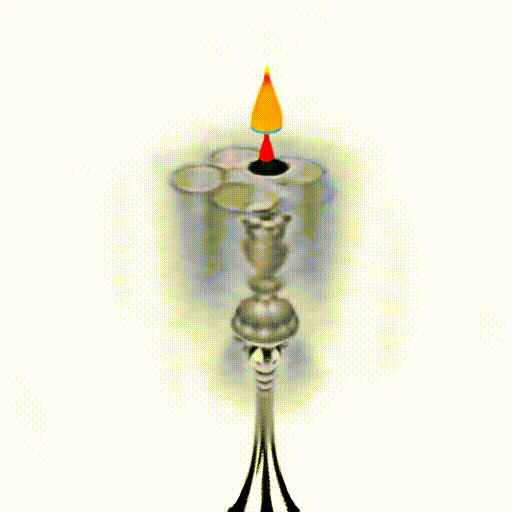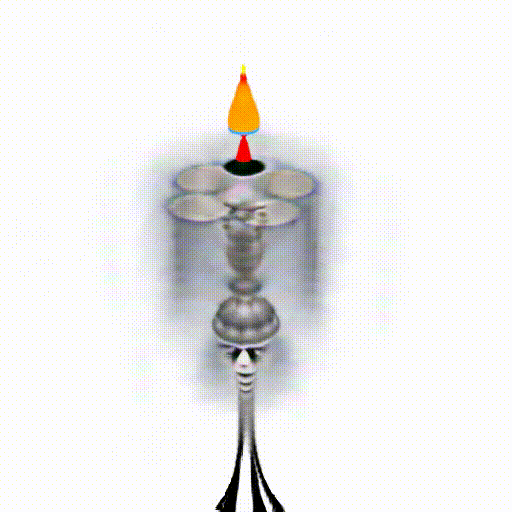
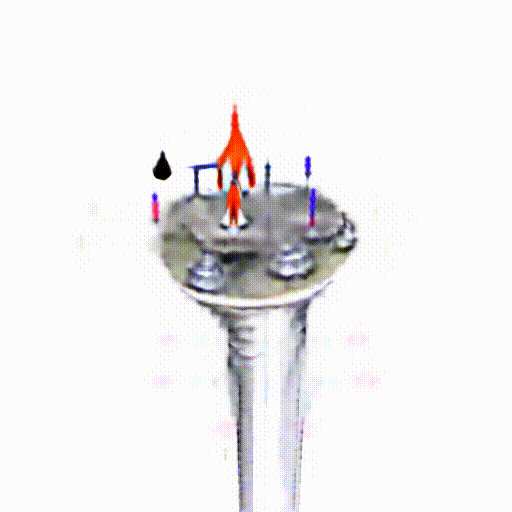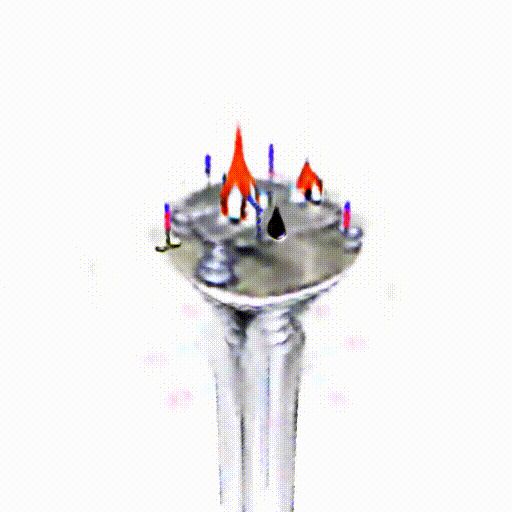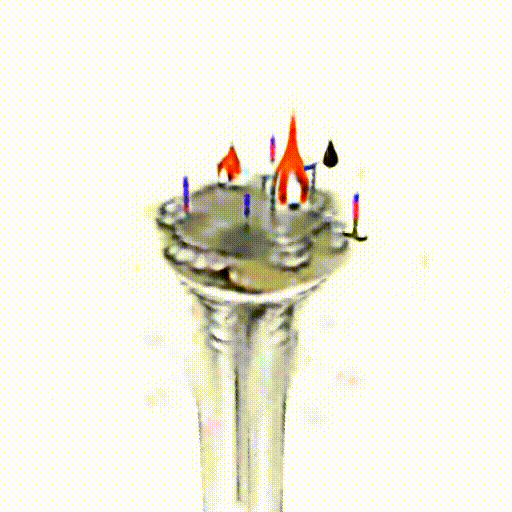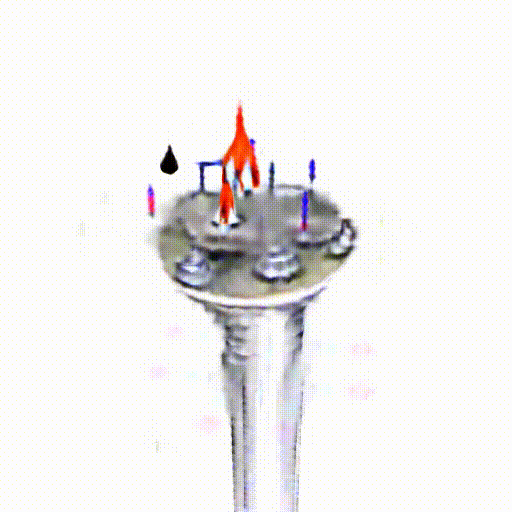
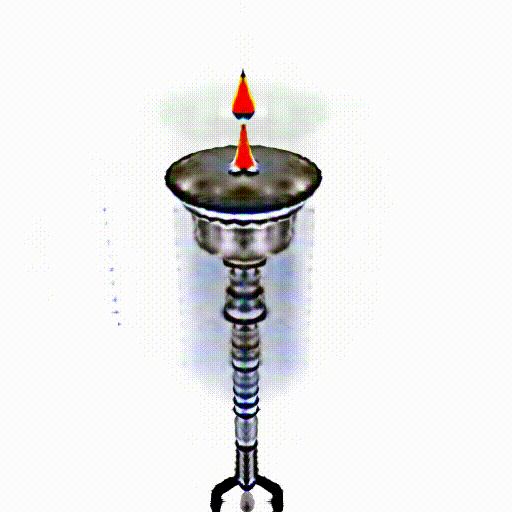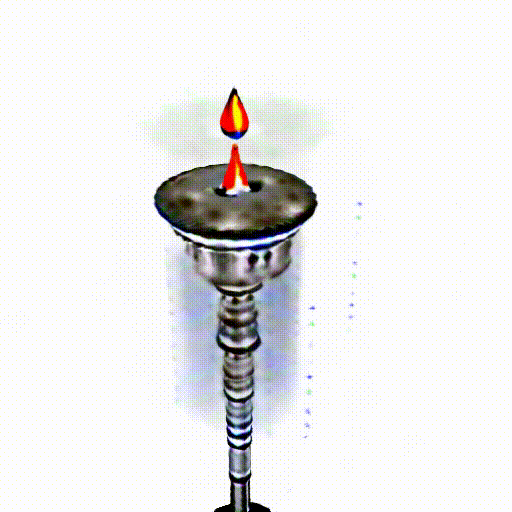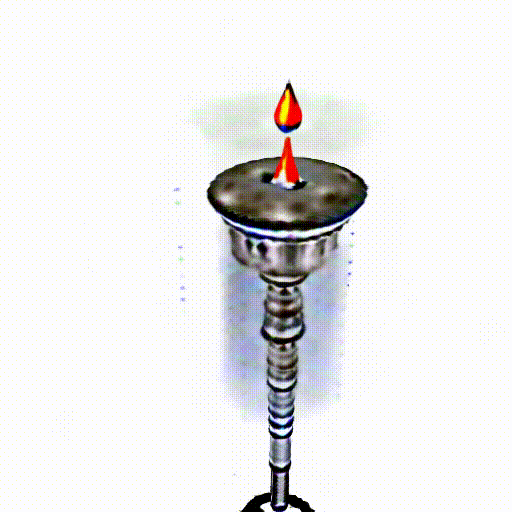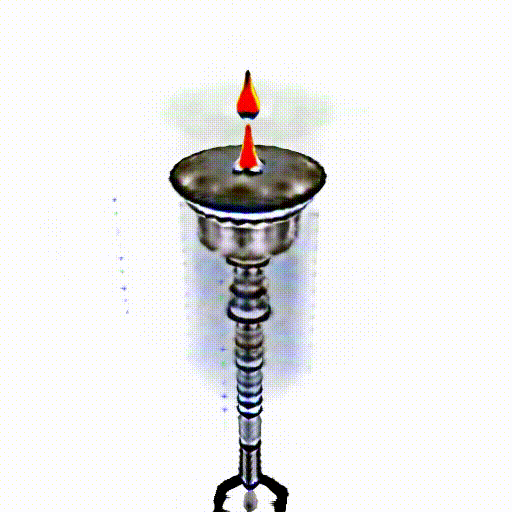
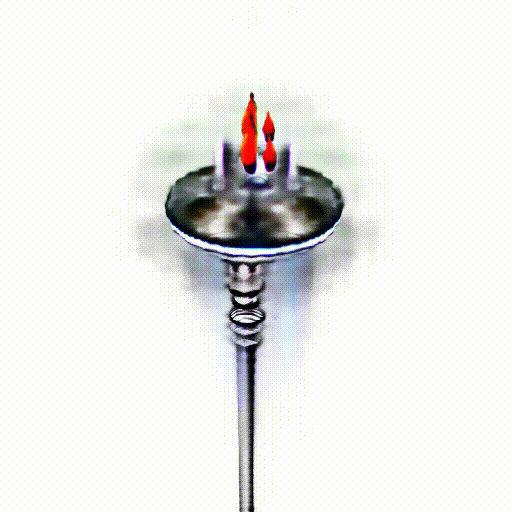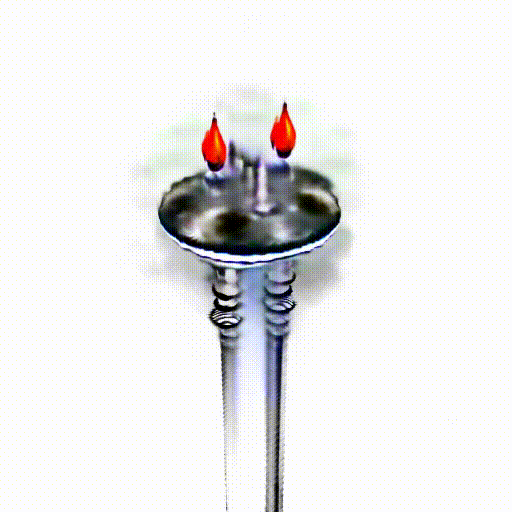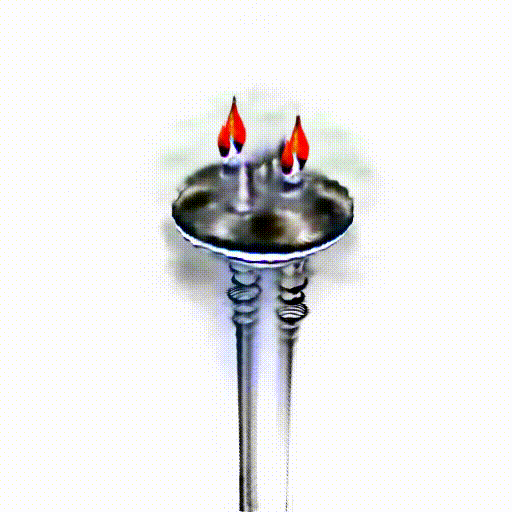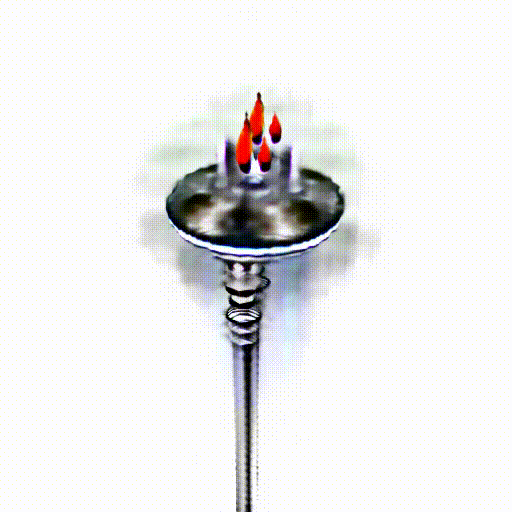
A silver candlestick with several burning candles.




A unique officer hat, black with gold trim, adds a sense of authority.




Tokyo city; trending on artstation.

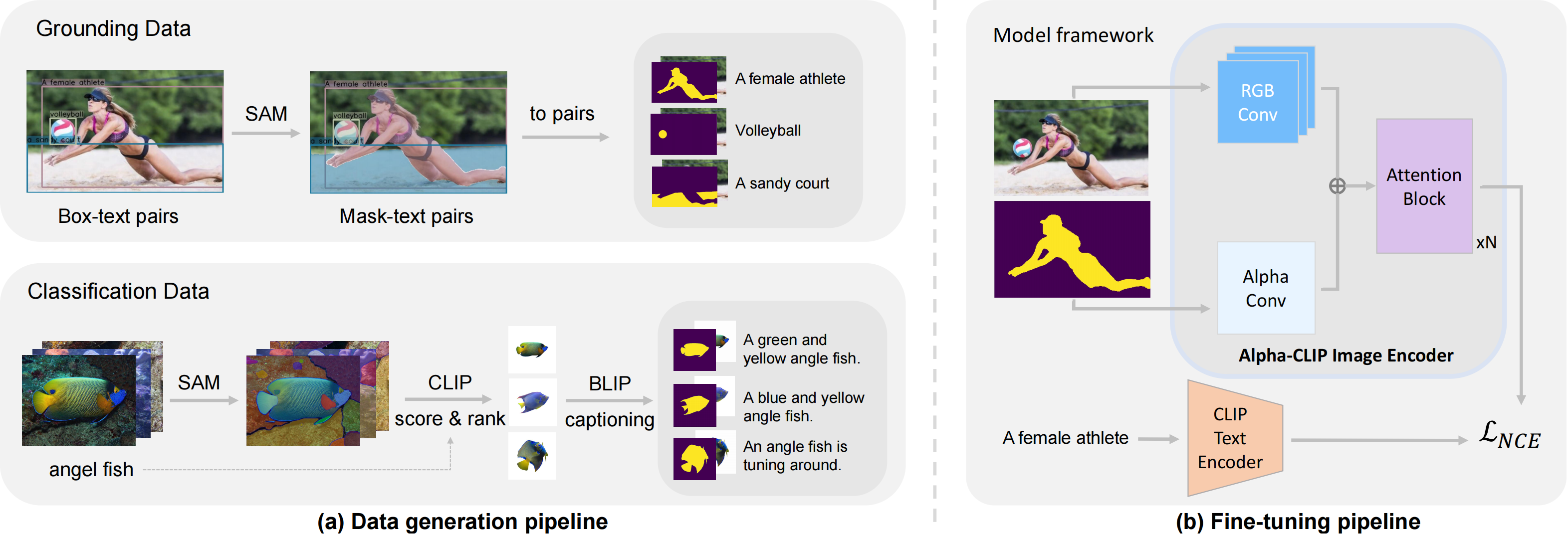
Alpha-CLIP Pipeline
The pipeline of our data generation method and model architecture. (a) Our method generates millions of RGBA region-text pairs. (b) Alpha-CLIP modifies the CLIP image encoder to take an additional alpha channel along with RGB. We first generate millions of RGBA region-text data from grounding and classification datasets. Using our generated data, we then train our Alpha-CLIP with additional Alpha-channel inputs.
Alpha-CLIP Attention Map Visualization
We check the attention map of [CLS] token in the last transformer block in the vision encoder.
Each first line per four is from original CLIP and the other three lines are from Alpha-CLIP with user-defined focus regions marked
in red. This visualization verifies that Alpha-CLIP pays more attention to the area to focus on and more importantly, with no damage to the 2D location information preserved in the feature location of the original CLIP.

BibTeX
@misc{sun2023alphaclip,
title={Alpha-CLIP: A CLIP Model Focusing on Wherever You Want},
author={Zeyi Sun and Ye Fang and Tong Wu and Pan Zhang and Yuhang Zang and Shu Kong and Yuanjun Xiong and Dahua Lin and Jiaqi Wang},
year={2023},
eprint={2312.03818},
archivePrefix={arXiv},
primaryClass={cs.CV}
}